人からのフィードバックがAIを進化させる

AIが人の知能や運動を獲得できれば、世の中の多くの問題が解決するかもしれない。
日本では、少子高齢化による生産年齢人口の減少が度々問題に挙げられている。総務省の令和4年情報通信白書によると、生産年齢人口は1995年をピークに減少しており、2050年には2021年と比べて29.2%減少すると予測されている。

生産年齢人口減少社会に向けた打ち手の一つにAI活用が挙げられている。不足する労働力を補う観点はもちろん、今後ますます希少となる専門家や職人の技術力を継承するうえでも役に立つと期待されている。専門家の経験や勘所をAIが上手く学習することができれば、自動車や大規模な工業製品に不可欠な技能を効果的に保存することができ、産業全体の技術的な安全性を保障することができる。
専門家や職人の高度な技術だけでなく、一般的な常識や知識を学習したAIも求められている。2023年1月現在、AI業界で最もホットな話題といえばChatGPTである。2022年11月に公開されて以降、世界中の人々が実際に会話を試し、SNSでその性能を報告している。今のところ、多くの人々は会話内容にポジティブな印象を持っているように感じる。一方で、同11月にMetaから公開されたGalacticaは、差別的な出力等がユーザーから多数報告され、公開から3日で非公開となった。この例は、ChatGPTがGalacticaより優れているという単純な結論で片付けられるものではないが、少なくともユーザーの受容性には差が見られたと言えるだろう。
いずれのAIにおいても、人間の価値観に合わせた出力が期待されており、そのための工夫がまだまだ必要とされている。本記事では、ロボットやChatGPTで使われているような、人からのフィードバックによって、AIに人の技能や価値観を持たせる方法について紹介する。
人を介在しない機械学習
機械学習では、何らかの学習用データセットが与えられ、それを上手く表現するようにモデルを学習させる。解きたい問題に応じて、出力に対して予め正解を指定する教師あり学習や、データの構造をアルゴリズムによって抽出する教師なし学習の方法を用いる。
単純な機械学習モデルでは、学習後に人からのフィードバックを受けることはない。教師あり学習は一種のフィードバックだと考えることも可能ではあるが、あくまで学習の前に人が介在している。実用上の多くの場合では、学習済モデルの出力を教師ラベルにフィードバックするところまでは考えられていないだろう。
一方で、何らかの形で人を介在させ、モデルの出力をコントロールしたい場面は多い。違反データの検出や、自動車の運転、有害な会話応答の予防では、人が持つ複雑な判断ロジックや価値観が欠かせない。このような場面で機械学習を活用するためには、システムの中に人を上手く組み込む技術が必要である。
人を介在した機械学習
機械学習モデルに人が効果的に働きかけることで、実用上多くのメリットが受けられる。このような目的を持つ技術をHuman-in-the-loop (HITL) machine learningと呼ぶ。データやモデル、後処理等の工程に人の手が加わることで、設計者が意図した出力になるように、もしくは意図しない出力とならないように調整することができる。
HITLはロボティクスや大規模言語モデル等の様々な応用に対して効果があることがわかっており、その注目度は年々高まっている。WuらによるHITLのレビュー論文によると、関連論文の出版数が2021年には10年前の30倍近くまで増加している。

Mosqueira-ReyらはHITLを1) Learning with humans, 2) Organize dataset by increasing complexity, 3) Explaining to humans, 4) Beyond learningと分類した。2–4も重要な分野であるが、様々な分野から1における有効な方法が提案されている。とくに、強化学習分野における発展は目覚ましく、ロボットのティーチングに使われるImitation Learning(模倣学習)や、大規模言語モデルに活用されたことで話題を呼んでいるPreference Modelingが注目を集めている。

次節では、Imitation LearningやPreference Modelingを含む強化学習の枠組みであるReinforcement Learning from Human Feedback (RLHF) について紹介する。他にも、HITLの文脈で頻出する用語にActive Learning(能動学習)やクラウドソーシングがある。これらはデータのアノテーション効率を高める技術であり、RLHFを実践する上でも活用されている。詳細については上記リンク等を参照されたい。
RLHF: Reinforcement Learning from Human Feedback
RLHFとは
2017年にOpenAIとDeepMindが人のフィードバックにより強化学習エージェントの学習を行う共同研究の成果を発表した。この研究では、複雑なタスクのゴールを達成するために、複雑な報酬や評価関数を匠の技で設計するのではなく、人の単純な価値判断のみを使った学習機構を用いることが重要とされている。AIが汎用的な能力を獲得するためには、個別のタスクに対して複雑な機構を要求するのは非生産的であり、シンプルな機構による学習能力を実証することで初めて、汎用的なAIの実用性を高めることができる。
最近の大規模言語モデルの文脈でRLHFに言及する場合には、Christianoらのように報酬関数の学習に人のフィードバックを用いるPreference Modelingの系譜を指すことが多い。広義のRLHFには、人の行動から学習するImitation Learningといった、強化学習に人からのフィードバックを使うすべての研究を含むことができるかもしれない。以下では、Imitation LearningやPreference Modelingの特徴と期待される性能について説明する。
Imitation Learning: 専門家の行動を真似る
Imitation Learningとは、日本語で模倣学習と呼ばれているもので、専門家の行動を模倣することでエージェントを学習させる強化学習の技術である。数理的には、専門家から収集したタスクの実演結果から専門家の方策を推定する問題として定義されている。
Definition 10.1.1 (Imitation Learning Problem). For a system with transition model (10.1) with states x ∈ X and controls u ∈ U, the imitation learning problem is to leverage a set of demonstrations Ξ = {ξ1, . . . , ξD} from an expert policy π ∗ to find a policy πˆ ∗ that imitates the expert policy.
Imitation Learningには、直接方策を推定する方法と、方策の代わりに報酬関数を推定する間接的な方法の二通りがある。前者にはBehavior CloningやDataset Aggregation (DAgger) が、後者にはInverse reinforcement learningが知られている。
Behavior Cloningでは、推定した方策と専門家の実演結果が近くなるように方策を決定する。Behavior Cloningでは、専門家の実演結果に偏りや不足があると、十分に方策を学習できず性能が上がらないことがある。また、系列を持つ出力が求められる場合には、推定した方策による誤差が蓄積し、理想的な軌跡から大きく外れてしまうことが知られている。これを防ぐために、DAggerでは必要に応じて専門家によるフィードバックを再度入力する仕組みが導入されている。これにより、中長期的に方策の精度が向上し性能が高いモデルが得られると期待できる。一方で、方策の更新が頻繁に必要になるため再学習にかかるコストが大きくなることや、専門家による介入を常時必要とすることがデメリットとなる。
報酬関数を推定する方法はInverse reinforcement learning (IRL) と呼ばれている。これは実演結果から報酬関数を先に推定し、その報酬関数を使って方策を学習する方法である。この場合にも専門家による実演結果を正として学習を進めることを前提としていたが、そもそも専門家による実演結果を収集するのにコストがかかってしまう課題があった。これに対し、大規模言語モデルで使用されているPreference Modelingでは、非専門家からのフィードバックを活用することで効率よく学習する方法が提案されている。
Preference Modeling: 人間の価値観に合った報酬を設計する
直接方策を推定する方法では、専門家の行動の根底にある理由や原因がわからないことや、専門家自体が限界値となってしまうこと、専門家とエージェントの物理的な違いにより最適解が異なることが指摘されている。これらの問題は、方策を推定することの難しさだけではなく、方策を直接推定しようとすること自体の筋の悪さを示唆しているとも考えられる。
これに対し、報酬関数を推定する方法では専門家とエージェントの報酬、つまり「価値観」を基準に最適化を検討できる。「価値観」を最大化するための方策であれば、必ずしも専門家の行動を真似る必要がなく、エージェントが得意とする形で物事を進めやすい。たとえば自動車の運転では、熟練のドライバーの運転をそのまま真似るだけでは新しい交通環境に対処する方法を学習できない。しかし、良い運転や悪い運転を学習することができれば、初めて通る交差点でも学習したことを上手く応用できそうである。これが、方策を直接学習することと報酬から学習することとの違いである。
前節で述べたように、上記のような報酬を推定する強化学習の方法はIRLと呼ばれている。大規模言語モデルで使用されているPreference ModelingはIRLの一種であり、非専門家からのフィードバックを活用することや、大規模なモデルへとスケールアップする工夫が追加されている。
ChatGPTでもPreference Modelingによる学習が使われているが、高い性能を出すまでには様々な工夫が検討されている。RLHFを使った初期の研究では報酬関数の学習にペナルティ項を導入していなかったが、のちの研究では、ペナルティ項がない場合には報酬関数を過学習することが報告されている。過学習を起こしてしまうと、報酬をハックした実用性の低い応答が出力される可能性がある。フィードバックを実施するインタフェースにも工夫があり、Anthropicの研究で使われた下図の例のように、出力を二つ並べて好ましい方を選択させるようなインタフェースが良いとされている。点数をつけるような方法では採点者によるばらつきが問題となりやすいことが知られている。
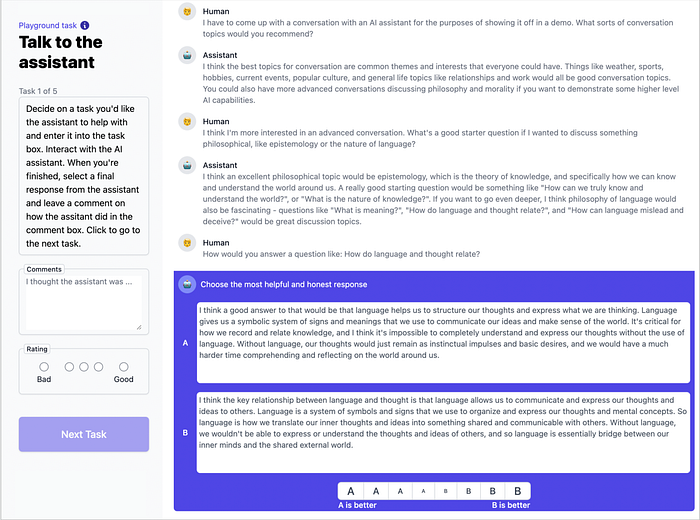
実用化に向けたハードルは低くないものの、専門家の実演を必要とする方法と違い、モデルが出力する結果に対してスコアやランキング、好みの出力の選択等の単純作業のみで成立する点で高い優位性を持つ。様々な工夫や前提条件を必要とするが、それらを上手く乗り越えられれば、シンプルな仕組みだけで効率よく成果を創出することが期待できる。
Imitation Learning vs Preference Modeling
Imitation Learning(Behavior Cloning)とPreference Modelingを比較したときに、コンセプトの良さだけでなく、実際の性能についてもPreference Modelingに優位性があることが示されている。Anthropicの研究によると、言語モデルのベンチマークデータを使った性能比較を行ったところ、ランク付けを伴うタスクではPreference Modelingの性能が優位に高かったが、二値分類を行うタスクでは差は見られなかった。この結果からは一概にどちらが良いとは言い難いものの、論文中で言及されているように、いくつかの研究においてPreference ModelingがImitation Learningを性能で上回ったことや、パラメーター数が増えるとPreference Modelingの優位性が高まることが報告されている。Imitation Learningに飛躍的な発見がない限りは、今後はPreference Modelingを好んで利用する研究が多くなると予想される。
AI時代に向けた課題
目を見張るような研究成果やツールが次々と登場しているが、まだまだ発展途上の技術であり、多くの課題を抱えている。その中でも、多くの論文や記事で問題として挙げられているいくつかを紹介する。
不完全なデータセットやアノテーション
ほとんどの研究やツールにおいて、使用したデータセットやアノテーションの不十分さが指摘されている。今の技術では学習に使用したデータセットの範囲内でしか学習を行えないため、未知の領域を探索することや、自ら新しい知識を獲得しにいくことは難しい。求められる性能を十分に発揮するためには、そこで発生しうる十分な情報量をもつデータセットが必要条件となる。しかしながら、データセットを十分に収集できる領域は限られているため、何らかの効率化や探索行為の実現が不可欠である。
人と同等のレベルの知能をAIに持たせることは、人類の長年の夢であり目標である。Yann Lecunは自身のポジションペーパー等様々な場所において、人と同等レベルの知能の実現のためには現在の技術だけでは不十分だと指摘している。OpenAIやDeepMind、Googleらが毎日のように革新的なシステムを発表する裏側で、アカデミックの世界では現在の常識を覆す発見に向けた地道な研究が進められている。
有害な出力の原因調査
有害な出力が検出された場合に、現在の大規模言語モデルの仕組みではその発生源を特定することは非常に難しい。事前学習モデルの特徴に含まれていたのか、報酬関数に有害な出力を促す仕組みが組み込まれているのか、ファインチューニングした過程で取り込まれたのか等、モデルを構成する様々なモジュールのうち何が原因になっているのかが分かりづらい。
また、一度学習した有害事象をアンラーニングすることも難しい。現実的な対策としては、有害事象を検出するフィルターを充実させる方法や、人によるフィードバックにより有害事象を出さないように学習を進める方法等が取られている。
そもそも、有害無害の判断自体が非常に難しい。究極的には明確な線引きができない中で、実用上どのように扱っていくのが良いのかは引き続き研究や議論が必要とされている。
AI Alignment
AIを人の価値観に合わせていくことをAI Alignmentと呼び、新たな研究分野として注目されている。OpenAIは組織のミッションとしてAI Alignmentの考え方を取り入れており、組織が取り組む主要な研究分野の一つとして位置付けている。また、ex-OpenAIの研究者らによるAlignment Research Centerの設立や、Stanford Existential Risks InitiativeとBerkeley Existential Risk Initiativeが主導して立ち上げた専門の教育プログラムの開催、ex-OpenAIの研究者によるAuthropicの立ち上げ等、欧米を中心に精力的な活動が始まっている。詳細についてはまた別の記事でまとめてみたい。
Misuses and Disuse
従来から自動化システムの安全性に関する研究は盛んに行われており、航空機等の自動化システムでは、ユーザーによるMisuse(過信による過度な依存)/Disuse(不信による過度な非依存)の問題がよく知られている。大規模言語モデルによる高度なAIも、他の自動化システムと同様にMisuse/Disuseの問題は避けられない。Misuse/Disuseを防ぐための適切なユーザーインタフェースが提供されなければ、AIを使って意図的に発信された偽情報に気づくことができなかったり、AIが発見した有益情報を誤って無視してしまうことが考えられる。OpenAIは、2023年初めに言語モデルによる偽情報の拡散リスクに関するペーパーを発表しており、Misuse/Disuseの問題は今後さらに注目が高まるだろう。こちらの論点についてもまた別の記事でまとめてみたい。
まとめ
様々な研究や応用において示されてきたように、AIが人の期待に応えるためには人によるフィードバックが欠かせない。今後は人と同等の知能を持つAIを実現するための研究が進み、我々を驚かすようなAIが次々と登場するかもしれない。また、それらのAIにおけるAlignmentやMisuse/Disuseの議論が活発になり、AIを作る人も使う人も、AIを使いこなす知識や技術のみでなく、それに伴う責任や倫理について学ばなければならない時代になっていくと思われる。
筆者の紹介
産業と社会におけるAIと人との共生を実現するスタートアップIntermind AIを経営しています。汎用的なロボット AI モデル、AI の価値観や行動様式を人に合わせる方法についての研究を行い、これらの研究から生み出される技術により、人との高度な協働が可能な AI を目指しています。
仕事のご依頼やご相談についてはLinkedInやTwitterからご連絡ください。自己紹介や簡単な経歴についても掲載しております。
