世界モデルでエージェントの知能をつくる

2022年11月30日にOpenAIからChatGPTがリリースされた。強化学習を用いて学習させた汎用のチャットAIである。
We’ve trained a model called ChatGPT which interacts in a conversational way. The dialogue format makes it possible for ChatGPT to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests. ChatGPT is a sibling model to InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response.
非常に高性能な会話能力を有しており、世界中の様々なユーザーが驚きとそのやり取りをSNSで報告している。OpenAIのブログにあるサンプルダイアログでは、プログラムの修正方法を知りたいユーザーが、会話を通じてChatGPTから問題のあるプログラムの箇所を教えてもらうというケースが紹介されている。

生成される文章はまるで人が書いたかのようなクオリティで、従来のAIと一線を画す。上の紹介文にもあるように、ユーザーとのこれまでの会話履歴を参照しつつ、新たに得られた情報を加味して適切な応答を生成してくれる。また、RLHF (reinforcement learning from human feedback)という技術を利用しており、人間の価値観に合わせた応答を生成するように調整されている。
強化学習はロボットの制御等の研究でよく知られた技術であるが、今後は会話や作業、意思決定等のあらゆるエージェント型AIを学習させる上で欠かせない技術となることは間違いない。本記事では、AIを用いたエージェント構築において強化学習がどのように役立つかを説明する。
強化学習によってAIエージェントを構築する
様々な研究機関や企業が強化学習によるAIエージェントの学習に取り組んできたが、最も有名なものの一つが2017年にDeepMindが発表した研究である。
一見奇妙な動きの棒人間が走り回るこの動画は、「コンピュータが独学で最善の方法として考案した行動」等の説明でメディアが取り上げたこともあり、SNSを中心に爆発的に広がった。ただならぬ動きに気を取られて研究内容が頭に入ってきにくいが、実際にはシンプルな報酬関数のみによってタスクに合わせた関節運動を獲得させようという野心的な研究内容だった。
冒頭のChatGPTのような例も出てきており、強化学習は技術的に成熟したと思われる方もいるかもしれないが、まだまだ発展途上の技術であり、様々な分野で広く使われるようになるためには解決すべき課題は多い。
強化学習の課題
強化学習の課題として、「外界の知識が不十分であるために学習が進まない」ことや「学習したいタスクを実践できなければ学習することが困難である」ことが挙げられる。前者の課題は、オセロのように環境が既知の問題であれば気にしなくても良いが、現実は未知の環境に適応することが求められる。後者の課題は、インベーダーゲームのように何度やり直してもデメリットがない場合には良いが、医療現場や公道の自動運転等の実環境における学習に危険を伴うケースに顕著である。
これらの問題を解決するためには様々な方法が提案されているが、以下では代表して「モデルベース強化学習」と「オフライン強化学習」の二つについて説明する。
モデルベース強化学習
モデルベース強化学習では、外界に対するモデルを使って方策を学習する。この反対にあるのはモデルフリー強化学習であり、外界に対するモデルを持たずに直接方策を学習する。学術的な詳しい説明はこちらを参照されたい。
外界に対するモデルを持つことで、方策学習の際にその知識を活用することができる。たとえば、次にこの制御をするとどうなるのか、その次にこの制御をするとどうなるのか、といった具合に方策によって起こり得る現象を予測することができる。また、外界に対する知識を十分に有したモデルを持っていると仮定すると、学習漏れを防いだり効率よく学習を進められると期待できる。
オフライン強化学習
強化学習と聞くと実際の現場でロボットを動かして学習させなければいけないイメージが強いが、必ずしもそういうわけではない。オフライン強化学習のコンセプトでは、自動車の運転のように本番での学習が困難な応用において、収集済のデータやそれを元に生成された環境を使って上手く方策を学習することができる。
収集済のデータを使うため、学習した方策には制限がある。たとえば、データセットに含まれていない部分を探索して学習することができなかったり、本番環境における分布シフトによって予測結果に偏りが生じることが挙げられる。
上記デメリットがありつつも、学術・産業界の様々な応用において期待されている。技術の詳細が知りたい場合はこちらの論文を参照されたい。
Sim2Real
本番での学習が困難な場合には、本番を模した環境をシミュレーションし、そのうえで方策を学習させることが考えられる。このように、シミュレーション上で学習させたものを実際の環境に適応させる技術をSim2Realと呼ぶ。技術の詳細が知りたい場合はこちらの資料を参照されたい。
シミュレーションを用いることで、安価で、高速に、大規模に、安全に学習を実行することができる。環境の編集やラベリングも容易であり、様々なケースに対応することができる。計算機と環境に対する情報さえあれば、理想的な制御方法を容易に獲得することができそうな夢の技術である。
しかしながら、シミュレーション環境自体の正確さや、外界を認識するセンサーやそのモデルの精度、その他様々な制約のために、シミュレーションで学習した通りに実機で動かすのは容易でない。我々の直感とは違い、小さなずれの積み重ねが想像を絶するほど大きなエラーを引き起こすことが知られている。
まだ有効な解決策があるとは言い難く、OpenAIも撤退したこの分野で成功を収めるのは容易ではない。ドメインアダプテーションやドメインランダマイゼーションをはじめとした、Sim2Realの性能を向上するための研究の更なる発展に期待したい。
世界モデルはAIエージェントの潜在能力を高める
前節で説明した、「モデルベース強化学習」、「オフライン強化学習」、「Sim2Real」のすべての性質を効果的に取り込んだ技術として、世界モデルがある。以下では、世界モデルについて概説し最新の関連研究成果の紹介を行う。
世界モデルとは
世界モデルは2018年にDavid Haによって提案されたモデルベース強化学習の技術である。世界モデルを用いると、強化学習を行う環境の潜在的な表現を学習し、エージェントの学習に役立てることができる。また、世界モデルではシミレーションによって生成した潜在空間上でエージェントを効率よく学習させることができる。前回の記事でもその概要を紹介した。
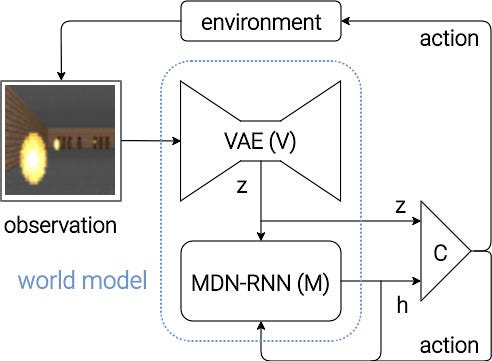
潜在空間における環境の表現
環境をモデル化する際に、そのモデルの表現力が大きな問題となる。モデルが上手く汎化していなければ、当然そのモデルを適用できる範囲は限定的になってしまう。モデルの表現が抽象的すぎる場合には、適用範囲は広いものの全てにおいて性能が低い「器用貧乏」になってしまう。汎用的なモデルを獲得することはあらゆるAI技術の課題であり、様々な研究者や技術者が競ってその方法を探している。
世界モデルの最初の論文では、環境の状態遷移をRNN (Recurrent Neural Network) とVAE (Variational Auto-Encoder)を使ってモデル化した。VAEは画像の圧縮や特徴量抽出等で使われることの多いモデルであり、データを支配するであろう低次元の潜在空間に特徴を落とし込むものである。この潜在空間における表現の状態遷移を確率的なモデルで取り扱うことで、高次元の環境データを効率よく処理することができる。
Dreamingによる学習
世界モデルでは潜在空間における状態遷移モデルを学習するため、そのモデルを使うことで方策に応じた環境の変化を予測することができる。
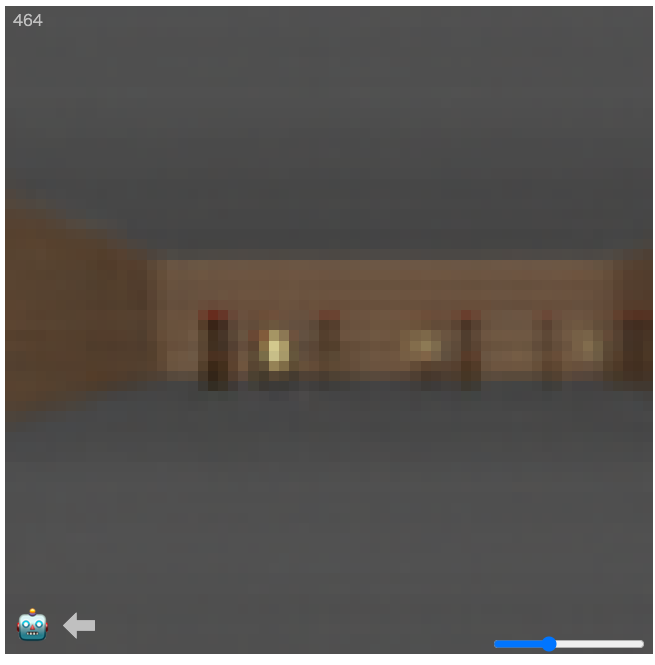
下図は学習した世界モデルによって生成された画像である。このモデルはあるゲームの環境を学習したものであり、ゲームプレイ中の状態の動きを適切に再現できている。Ha氏はこれをDreamingと呼んでおり、世界モデルによってゲームの世界を想像したようなシミュレーションができていることがわかる。
ゲームの世界を想像できるということは、その想像を使って方策を学習することも考えられる。論文中では実際にゲームの操作を学習させて、ゲームをプレイさせている。下図は実際に世界モデル上で学習した強化学習エージェントがゲームをプレイしたときの画像である。より詳しい説明や実際のプレイ動画については論文ページを参照されたい。
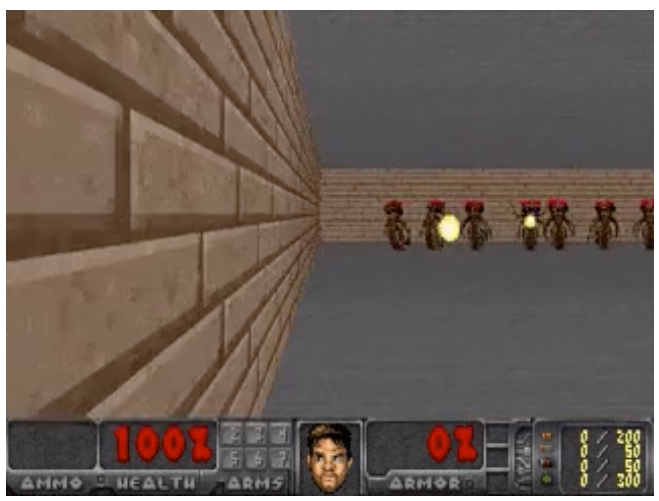
Dreamingという仕組みを用いることで、実際の環境とのインタラクションをせずにエージェントの方策を学び、それを実際の環境に適用して動かすことができた。これはまさに、モデルベース強化学習が生み出す環境によって実行するオフライン強化学習であり、実際の環境に適応させるSim2Realの実演である。
世界モデル論文の出版当初ではモデルフリーの方法にも及ばなかったものの、現在ではAtariのゲームで高性能の記録を叩き出す研究や、2Dから3Dまで様々なゲームに対して汎用的に適用可能なモデル等、その威力が様々な研究によって認められてきている。環境のモデルの学習効率が上がれば上がるほど、更なる性能向上が期待できることは間違いない。
Transformerの適用
昨今の大規模言語モデルやGenerative AIの流行を支えているのが、Transformerと呼ばれる技術である。Transformerはディープラーニングのネットワークの一種であり、画像やテキスト、音声等の様々なモデルにおいて導入が進んでいる。
TransformerはRNNと同様に、系列を持ったデータから効率よく特徴を抽出することが知られている。Transformerという仕組みが提案されたのは、Attention Is All You Needというディープラーニングの研究者であれば知らない人はいないであろう論文である。Transformerの解説だけで一本記事が書けてしまうので、詳細はオムロンサイニックエックス牛久先生の資料やソニーのNeural Network Consoleを使った解説動画を参照されたい。
強化学習でもTransformerを注目を集めており、世界モデルにおいても元の世界モデル論文にてRNNを採用していた部分をTransformerに置き換えた研究が登場している。RNNベースのものを性能で上回ったと報告した研究や、Transformerを用いて短時間で効率よくAtariベンチマークの世界モデルを学習したとする研究もある。多領域で報告されているTransformerのメリットが世界モデルでも実証されつつあり、今後の発展が大いに期待されている。
Decision Transformerによる強化学習のゲームチェンジ
前節で説明したように、Transformerの衝撃は強化学習にも波及している。Decision Transformerと呼ばれる技術では、従来の強化学習の概念を覆すような学習方法により、エージェントの方策学習が実証されている。
Decision Transformerとは
Decision Transformerとは、UC BerkleyとFacebook AI Research、Google Brainの研究者達によって提案された強化学習のフレームワークである。従来の強化学習の特徴である状態遷移関数、価値関数、報酬関数といった仕組みを一切捨てて、理想的な報酬と状態、方策の三つの時系列を入力としたトランスフォーマーモデルを学習する。
トランスフォーマーモデルのメリットとしては、言語モデル等と同様に系列のコンテキストを考慮できる点が挙げられる。提案論文では、強化学習で問題になりやすいlong-term credit assignmentやスパースな報酬環境でも上手く扱えることが実証されている。つまり、従来の方法では苦手とされていた学習がDecision Transformerでは見事に克服されているのである。
汎用的な能力を獲得したRT-1
Decision Transformerの研究に続いてGoogleから発表されたのがRT-1である。自然言語で表現された入力とカメラから取得した画像をトークン化し、ロボットのアクショントークンを出力するモデルである。ロボットのアクショントークンを生成する部分には、Decision Transformerにインスパイアされてトランスフォーマーアーキテクチャーが採用されている。
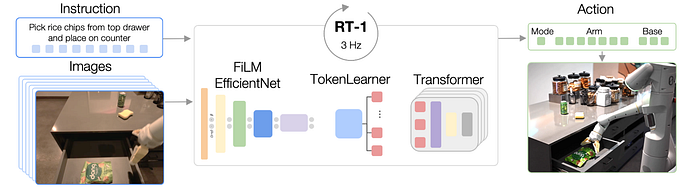
RT-1は様々なタスクに汎化したロボットをリアルタイムに制御することを目的としており、モデルの表現能力だけでなく効率も重視した設計がなされている。入力の6枚の画像を圧縮する部分には、表現効率の高いEfficientNetが利用されている。また、トークンの圧縮プロセスを中間に効果的に配置することで、効率の良いモデルを実現している。これらの工夫により、100ms以上の遅延を許容しない制御環境においても上手く動作するシステムとなっている。
検証では学習に使用したタスクだけでなく、未知のタスクも試験されている。GatoやBC-Zといった話題の汎用強化学習手法と比較し、いずれの条件においてもRT-1が圧倒的に優れた成績を収めることができた。
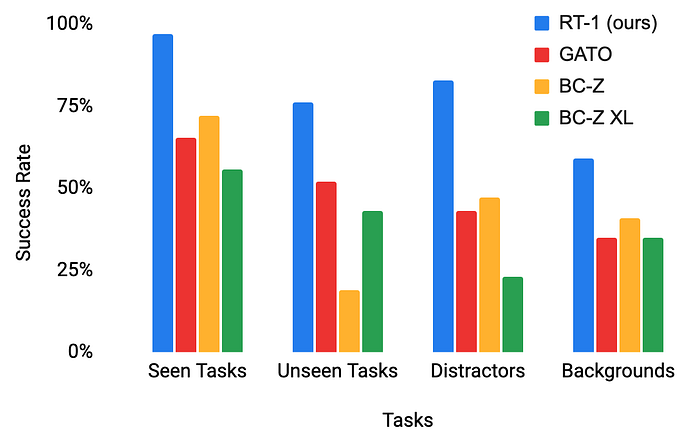
RT-1論文では三つの制約事項が明記されている。一つ目は、模倣学習を用いているためデモンストレーターの性能を上回ることができない点である。二つ目は、新しいタスクへの汎化はあくまでRT-1が経験したアクションの組合せに限られるため完全に新しい動きを表現することは難しい点である。三つ目は、学習したデータは大規模であるものの、そこそこのマニピュレーションタスクのものに限られる点である。これらを克服することができれば、より広範囲に汎化し、様々な環境にもロバストな動きを実現できるかもしれない。
RT-1論文の著者の一人であるKarol HausmanのTweetでは、LLMは巨大なデータセットを学習して汎用的な能力を得ることができたが、現状の強化学習の技術では同様の現象は見られないと述べられている。また、そういった強化学習の制約を認識していたため、RT-1では強化学習ではなくDecision Transformerの系譜による実装を考えたと言及している。
他にもTransformerを用いた強化学習の研究は多数存在する。さらに詳しい情報を必要とする場合には、最新のサーベイ論文を参照されたい。実装を交えた日本語の解説についてはこちらがおすすめである。
AIエージェントの更なる進化に向けて
大規模モデルの可能性
Karol HausmanのTweetの一連のスレッドで挙げられているような強化学習の学習性能の改善が進む中で、強化学習においても大規模モデルの可能性が少しずつ示されている。学習以外にも、言語モデルや画像生成モデルと大きく異なる点は、処理のリアルタイム性や入力に対する頑健性への要求が厳しい点が挙げられる。大規模モデルを効果的に扱うためには、これらの問題に対する効果的な解決策が求められるだろう。
大規模モデルを検討するうえで最も大きな課題となるのがデータセットである。ロボットのデータセットは言語や画像と比べるとまだまだ少なく、実環境で収集するには多大なコストを要する。シミュレーションによって効率よくデータセットを構築することが必要となってくるが、やはり先に述べたようなSim2Real特有の課題に直面することは避けられない。このような現実的な制約の中で、いかにモデルを学習させるかが次なる飛躍への鍵となるだろう。
Yann Lecunの構想
AI研究者のYann Lecunは、2022年の初めにMeta AIのブログにて自身の研究構想を述べている。その中に、AIのシステムアーキテクチャーとして提示された1枚の画像がある。

この中では、世界モデルが外界の認識と脳内の処理をつなぐ重要な役割を担っており、Yann Lecunがイメージする脳の処理機構において世界モデルが非常に興味深い位置づけとなっていることがわかる。実際に、記事中でも世界モデルを最も複雑なピースだとして説明している。
さらに興味深いのは、Configulatorと呼ばれるモジュールが存在することである。これは、様々なモジュールを繋いで複雑な思考を実現する部分として考えられている。Yoshua Bengio、Yann Lecun、Geoffrey Hintonがまとめたレビューでは、今後のAIの課題として高次の認知機能の実現が挙げられている。現在の大規模言語モデル等の躍進は、あくまで直感的な認知機能を模擬できた段階に過ぎず、物事の複雑な構造や関係を理解するには至っていない。高次の認知機能を持ったエージェントを実現するためには、上図のConfigulatorのようなモジュールに相当する仕組みが必要であると考えられている。
詳細な説明は上記ブログの元となるYann Lecunのポジションペーパーや、松尾先生やYann Lecunらが参加するレビュー論文を参照されたい。
まとめ
世界モデルは大変注目を集めている重要な技術であり、その前後の技術を含めて次世代のエージェントシステムの要の技術になると期待されている。強化学習は日々進化しており、世界モデルにとどまらず様々なフレームワークやアーキテクチャーが提案され、これまでにないスピードで進化し続けている。いずれにおいても基本的な方向性は、有効な潜在表現の獲得や新しい環境への汎化であり、AIのすべての分野に通ずるものである。
本記事内で紹介した技術はすでに世の中で利用可能であり、実証研究レベルであればどんどん活用できるだろう。エージェントの知能の学習は様々な応用が考えられるため、各々が持つ課題の中で適切なものが見つかるはずである。本記事を参考に、ぜひ活用アイディアを議論していただきたい。
筆者の紹介
産業と社会におけるAIと人との共生を実現するスタートアップIntermind AIを経営しています。汎用的なロボット AI モデル、AI の価値観や行動様式を人に合わせる方法についての研究を行い、これらの研究から生み出される技術により、人との高度な協働が可能な AI を目指しています。
仕事のご依頼やご相談についてはLinkedInやTwitterからご連絡ください。自己紹介や簡単な経歴についても掲載しております。




