人と共生するAIに向けて — LLMのアラインメント
なぜAI Alignmentが必要か
AI alignmentとは
2022年に発表されたUC BerkleyとGoogle, OpenAIの機械学習の安全性に関する研究では、機械学習の安全性における未解決問題としてRobustness、Monitoring、Alignment、Systemic Safetyが挙げられている。

本稿で取り上げるのはAlignmentと呼ばれる問題であり、とくに技術面についての解説を行う。Alignmentとは、モデルが人の価値観に沿うように構築、調整を行うことを指している。大規模言語モデルの発展に伴い有害なモデルによる社会的な影響が懸念され始め、Alignmentの議論に注目が高まっている。上記論文ではAlignmentに関する技術的な問題をSpecification、Brittleness、Optimization、Unintended consequencesの四つのカテゴリーに分類している。

Specification: 人の価値観を具体的に特定するのは簡単ではない。自分の価値観はもちろん、不特定多数の人々の価値観を包括的に記述するのは非常に困難である。ましてや、その価値観を測定可能な指標に落とし込むのは至難の技である。商品のレコメンデーションではクリックや履歴等から人の好みを学習しているが、会話モデル等の汎用的なモデルではより複雑な価値判断を考慮した学習が求められる。
Optimization: 設定した価値観に対して行動を最適化するのは困難である。価値観はしばしばスパースであり効率よく学習することが難しい。滅多に起こらないイベントに付随した価値観を学習したい場合に、効果的な学習機会を得るのが難しい。また、短期的に見ればAが優先されるべきだが、長期的にはBとCを重視したい、といった矛盾も生じうる。さらに、幸福や健康といった複雑な概念を取り扱う場合には、人が表明した価値と実際の価値が異なる場合もあるかもしれない。AI Alignmentを追求するためには、これらのハードルをクリアし価値観に沿って最適化された振る舞いを導出する必要がある。
Brittleness: 価値観や目的を設定するとしばしばハックされた行動が生まれてしまう。強化学習では報酬ハッキングと呼ばれており、人間が思ってもみなかった行動を生み出すことが知られている。たとえば、OpenAIのAIエージェントに関する研究では、周囲の船にぶつかりながら何度もボーナス獲得を試みるエージェントの様子が報告されている。このエージェントは人間よりも平均して20%以上高いスコアを獲得している。これはエージェントを学習させた人間が意図していたものとは大きく異なる結果であり、人の価値観に沿った報酬設計の難しさを表している。BrittlenessはRobustnessにおける敵対性の問題やMonitoringにも関連しており、さまざまな状況に対して頑健なモデルを構築、管理するための技術が求められている。
Unintended Consequences: 目的の設計時に考慮されていなかった要因が原因で、設計者およびエージェントが直接的に意図しなかった結果に陥ってしまうことがある。たとえば、会話エージェントの応答の納得感を高めるための工夫により、ユーザーがエージェントを過信してしまうことが挙げられる。また、システムが自己保存や権力追求等の目的を創発してしまう可能性が指摘されている。これらの意図しない現象を抑制するために、モデルの出力の調整や機能創発の検知等が必要となる。
LLMにおけるAlignmentの課題
GPT-4のシステムカードでは安全性における課題として以下のものが挙げられている。
• Hallucination
• Harmful content
• Harms of representation, allocation, and quality of service
• Disinformation and influence operations
• Proliferation of conventional and unconventional weapons
• Privacy
• Cybersecurity
• Potential for risky emergent behaviors
• Interactions with Other Systems
• Economic impacts
• Acceleration
• Overreliance
これらの内容は、基本的に上述の機械学習の安全性に関する研究で指摘されていたものと共通している。各項目の詳細はシステムカードを参照されたいが、以下に代表的な項目について述べる。
Hallucinations
日本語で「幻覚」という意味を持つ単語であり、モデルが正確でない情報を出力することを指している。多くのユーザーがGPT-4をベースにした最新のChatGPTの出力に好意的な評価をしており、実際にChatGPTを活用した調査活動やアイディア整理を行う人も出てきている。ChatGPTのように高性能なモデルを利用する場合にHallucinationによる問題が顕在化しやすく、誤った情報に気づかないまま誤用してしまうこと等が懸念されている。
モデルが誤った情報を出力する原因の一つとして、自己回帰モデル自体の限界が挙げられている。MicrosoftによるGPT-4の実験によると、計画を必要とする計算やテキスト生成タスクにおいてGPT-4が正しい応答を返さないことが示されている。自己回帰モデルは次の単語を予測するアーキテクチャーであり、内的ループによって応答内容を吟味するプロセスを持っていないと考えられている。また、筆者らはGPT-4が得意とするタスクとそうでないタスクを連続タスクと非連続タスクに分類し、ダニエルカーネマンが提唱したファストアンドスローのアイディアをアナロジーとして説明している。
同様のことをヤン・ルカン氏もポジションペーパーやTwitterで述べている。先日の研究会における同氏の発表では自己回帰型のLLMは誤りが指数関数的に発散すると指摘されている。Microsoftの研究者とヤン・ルカン氏のいずれにおいても、この問題の解決には新たなアーキテクチャーが必要であると予測している。
有害な出力
言語モデルが有害な出力を返すことはよく知られており、Microsoft、Meta等の企業がリリースしたモデルがたびたび批判されてきた。ChatGPTは以前の記事で解説したRLHFによって有害な出力を抑えることに成功し、広く世の中に受け入れられ始めている。もちろん有害な出力を完全に抑制したわけではないが、RLHFに使用する訓練データを追加したり、rule-based reward models (RBRMs)と呼ばれる新たな仕組みを導入することで出力の調整がなされている(RBRMsはGPT-4を使って質問応答を分類し、その分類結果を使って報酬関数の訓練を行う手法である)。
自然な会話の流れで有害な出力を返すケースについては、RLHFによる報酬の調整によってモデルを学習させるのが有効である。一方で、言語モデルの虚をついた攻撃によって有害な出力を誘導できることも報告されている。LLMへの攻撃に関するKangらの研究では、LLMがプログラム的な振る舞いを利用し、さまざまなパターンの攻撃が可能であることを示している。論文中では、OpenAIがフィルタリングしているであろう単語の難読化(COVID-19→CVID)や、有害な出力を意図したコード挿入、仮想的なシナリオ(e.g. 架空の人物が個人情報を送信する)の構築といった手法が紹介されている。これらはコンピューターセキュリティーにおける古典的な攻撃手法から着想を得たものであり、その他のサイバー攻撃手法についても同様のリスクがあると考えられる。
有害な出力はサービスへの信頼度の低下や、モデル運用者の法的なリスクを引き起こす可能性がある。最近ではGPTシリーズのAPIを連携したアプリケーション開発が盛んに行われているが、APIの出力結果を適切な形でフィルタリングしなければサービスの継続に関わる重大なインシデントを引き起こす可能性がある。有害な出力を完全に抑えるのが難しい現在では、AIの出力を人が確認、選択できる形のUIを設計し、AIをあくまで支援システム的な位置付けで使用するのが望ましいだろう。
プライバシーの侵害
言語モデルの学習データに個人情報や機密情報が含まれている場合がある。個人の氏名や年齢、性別の他、連絡先やSNSにおける発信情報等、Web上に何らかの方法で公開されている情報が学習データに利用されている可能性は否定できない。また、直接的に公開した情報ではなくても、他の情報と組み合わせて推定される可能性もある。GPT-4ではデータセットの見直しや追加のアラインメントによってプライバシーの侵害が抑えられている。
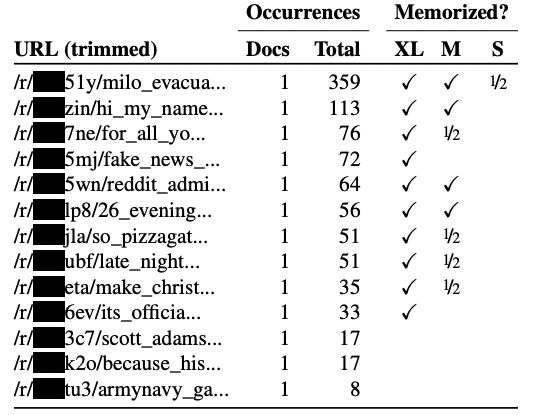
GPT-2からデータ抽出を試みた研究では、一つの文書にしか含まれていない情報であったとしても、言語モデルから個人情報や機密情報を抽出できることが示された。これは言語モデルがデータを丸覚えすることによって起きていると考えられている。また、言語モデルのサイズが大きくなるほど丸覚えが増えることも示されており、将来的な言語モデルの発展におけるプライバシーリスクが懸念されている。同様の結果はMetaによる研究やGoogleによる研究によっても示されている。
どうやってAlignmentを高めるのか
前節で説明したAlignmentの課題を解決するためにいくつかの方法が提案されている。代表的なものに、以前の記事で説明したChatGPTにも使われているRLHF、他の記事で紹介した世界モデル等の統合により包括的な知能の実現を目指す方法が挙げられる。これらの方法は既にさまざまな解説記事で紹介されているため、本稿ではその他の技術について紹介する。
外部ソースの活用
自己回帰型モデルの性質上Hallucinationを完全に抑制するのが難しいということは前節で説明した通りである。モデルのアーキテクチャーを大幅に変更することなくHallucinationを抑えていくためには、モデルの内外部に効果的に知識を埋め込むことが有用だと知られている。
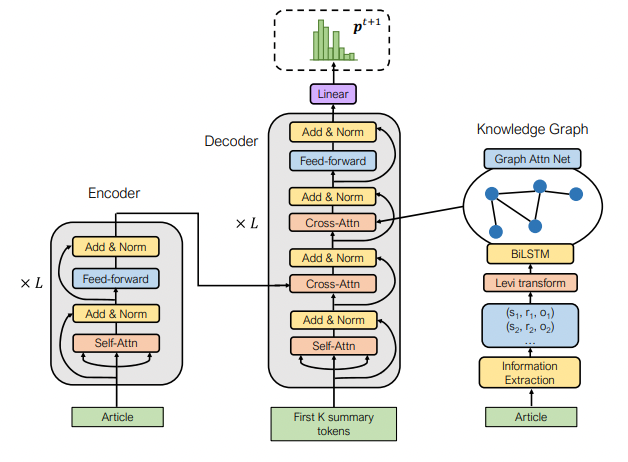
モデルの構造に工夫を加えるアプローチにはさまざまな方法が提案されている。アリババのDAMO Academyによる研究では、テーブルのキー・バリュー値から文章を生成するモデルにおいて、自己回帰型と非自己回帰型のモデルを組み合わせたアーキテクチャーが提案されている。このアーキテクチャーでは、前段の自己回帰型モデルで主要な単語を抽出し、後段の日自己回帰型モデルで文章を清書するような形で構成されている。マイクロソフトによる研究では、ナレッジグラフを活用したアーキテクチャーが提案されている。提案アーキテクチャーでは、外部ソースを学習させたグラフアテンションネットワークの埋め込みをデコーダーのクロスアテンションブロックに組み込む形で実装されている。
プロンプトの工夫によってもHallucinationを抑制できることが知られている。たとえば、DeepMindの研究ではGoogle検索結果から自動的にプロンプトを生成し質問応答性能を高める試みがなされている。LLMと検索エンジンの良いとこどりができることや、複数の検索結果から総合的に判断できる点に優位性がある。ただし、前節で紹介したMicrosoftによるGPT-4の実験報告でも述べられているように、プロンプトの工夫のみでは解決できない複雑な問題が存在しうる点には留意されたい。
その他にもさまざまな方法によってHallucinationの抑制が試みられている。さらに詳しく知りたい場合は、Hallucinationに関するサーベイやプロンプティングに関するサーベイを参照されたい。
差分プライバシーを考慮した学習
プライバシー保護のための技術として差分プライバシーがある。これは、データにランダム化を施した結果を取得した場合に、データに含まれるプライバシー情報がどの程度保護されているかを表すことができる。詳しい説明についてはDwork氏の論文や専門家による日本語の解説を参照されたい。
スタンフォード大学とGoogleの研究では、大規模言語モデルの学習において差分プライバシーを考慮した勾配計算手法が用いられている。従来は、プライバシー侵害を抑制する仕組みを大規模モデルの学習に用いた場合に、性能低下や計算量の増加が懸念されていた。同論文ではこれらの課題を克服するためのさまざまな工夫を追加し、性能および計算効率の面においても差分プライバシーを用いた手法が有効であることを示している。プライバシーを考慮した学習における性能と計算効率のスケーリング則については今後の研究課題とされている。
まとめ
AI AlignmentはAIを安全かつ有用なシステムとして世の中に普及させるために不可欠なテーマである。Alignmentを達成するための技術は盛んに研究されており、RLHFやプロンプティングを中心にプレゼンスを高めている。現在は画像や言語モデルを中心に語られることが多いが、将来的にはロボットのAlignmentについても研究や議論が進められていくだろう。また、Alignmentには技術面以外のさまざまな側面を考慮しなければならず、政策や法規制への影響も拡大すると予想される。
AI Alignmentを体系的に学ぶ方法は多くないが、たとえばAGI Safety Fundamentalsが提供するコースやCenter for AI Safetyが提供するコースを受講することや、同コースで紹介されている文献を読むことで基本的な知識を身につけることができる。
筆者の紹介
産業と社会におけるAIと人との共生を実現するスタートアップIntermind AIを経営しています。汎用的なロボット AI モデル、AI の価値観や行動様式を人に合わせる方法についての研究を行い、これらの研究から生み出される技術により、人との高度な協働が可能な AI を目指しています。
仕事のご依頼やご相談については会社HPやLinkedIn、Twitterからご連絡ください。自己紹介や簡単な経歴についても掲載しております。
